고정 헤더 영역
상세 컨텐츠
본문

반응형
SMALL
이번 게시물은 가장 중요한 시간(time) 데이터, 즉 시계열 데이터를 다루는 다양한 방법을 다룰 것이다. 금융권에서 시계열 데이터는 항상 접하는 것이기 때문에 해당 게시물을 통해 시간 데이터를 능숙하게 다룰 수 있도록 해 보자. 파이썬 패키지인 데이트타임(datetime), 넘파이(numpy), 판다스(pandas)에서 시간 데이터를 어떻게 다루는지 살펴볼 예정이다. 언급한 3가지 패키지는 데이터 분석에서 매우 중요하기 때문에 패키지 이름, 역할에 대해서만큼은 꼭 기억하기를 권장한다. 세세한 기능은 추후에 찾아보면서 진행하면 되기 때문에 핵심 기능만 기억하면 된다.
[ 데이트타임(Datetime) ]
파이썬 표준 패키지인 Datetime에 대해 살펴보자. 해당 패키지에는 날짜와 시간 관련 함수가 있다. 해당 함수는 String 타입의 문자를 날짜 형태의 format으로 바꾸거나 시간 단위 변경, 시각화 등에 응용할 수 있다. 해당 패키지에 내장된 핵심 클래스에 대해 정리하면 아래와 같다.
- time: 시간 기능만 제공한다. (시, 분, 초, 마이크로초)
Ex) datetime.time (hour=4, minute=3, second=10, microsecond=1000) - date: 날짜 기능만 제공한다. (연, 월, 일)
Ex) datetime.date (year=2023, month=3, day=25) - datetime: 날짜와 시간 기능을 제공한다. (date + time)
Ex) datetime.datetime (year=2023, month=11, day=13, hour=10, minute=6, second=10, microsecond=1000) - timedelta: datetime 인스턴스 간의 차이를 구함. 산술 연산자 '+'와 '-'를 사용하여 특정 날짜에 원하는 기간(일, 시, 분, 초)을 더하거나 뺄 수 있다.
실제 분석에서 날짜와 시간은 문자열 타입으로 주어진다. 따라서 문자열 데이터를 날짜 형식으로 변환해야 한다. 아래의 실습을 통해 날짜 변환(conversion)에 대해 알아보자.
- string type을 datetime type으로 변환
import datetime
datetime_str = '2023-11-14 02:47:18' # 날짜를 문자열 형태로 입력 받음.
format = '%Y-%m-%d %H:%M:%S' # 포맷 코드를 활용하여 형식 지정
# 입력한 string type의 날짜와 날짜를 표현하는 형식을 strptime 메서드에 전달하여 datetime_dt 변수에 저장.
datetime_dt = datetime.datetime.strptime(datetime_str, format)
print(type(datetime_dt)) # datetime_dt 변수의 type 확인
# 출력 결과
<class 'datetime.datetime'> # string 타입 -> datetime 타입으로 변환됨.- datetime type을 string type으로 변환
# datetime_dt 변수를 통해 strftime 메서드 호출 -> 변환하려는 날짜와 시각을 인자로 전달
datetime_str = datetime_dt.strftime('%Y-%m-%d %H:%M:%S')
print(type(datetime_str)) # datetime_str 변수의 type 확인
print(datetime_str) # datetime_str 값 출력
# 출력 화면
<class 'str'> # datetime 타입 -> string 타입으로 변환됨.
2023-11-14 02:47:18- 시간까지만 출력(분, 초 제외)
datetime_str = datetime_dt.strftime('%Y-%m-%d %H')
print(type(datetime_str))
print(datetime_str)
# 출력 화면
<class 'str'>
2023-11-14 02 # 시간까지만 출력됨- 년도와 달까지만 출력
datetime_str = datetime_dt.strftime('%Y-%m')
print(type(datetime_str))
print(datetime_str)
# 출력 화면
<class 'str'>
2023-11 # 연도와 달만 출력됨정리하면, '%Y-%m-%d %H' 형식을 전달하면 '연-월-일 시' 형식으로 출력되고, '%Y-%m'을 전달하면 연-월만 출력된다. 아래의 표를 통해 날짜/시간 포맷 코드를 정리해 보자.
| 코드 | 설명 | 예시 |
| %a | 요일 줄임말 | Sun, Mon, ..., Sat |
| %A | 요일 | Sunday, Monday, ..., Saturday |
| %w | 요일을 숫자로 표시한 것, 월요일~일요일(0~6) | 0, 1, ..., 6 |
| %d | 일 | 01, 02, ..., 31 |
| %b | 월 줄임말 | Jan, Feb, ..., Dec |
| %B | 월 | January, February, ..., December |
| %m | 숫자 월 | 01, 02, ..., 12 |
| %y | 두 자릿수 연도 | 00, 01, ..., 23 |
| %Y | 네 자릿수 연도 | 2000, 2001, ..., 2023 |
| %H | 시간(24시간) | 00, 01, ..., 23 |
| %I | 시간(12시간) | 01, 02, ..., 12 |
| %p | AM, PM | AM, PM |
| %M | 분 | 00, 01, ..., 59 |
| %S | 초 | 00, 01, ..., 59 |
| %Z | 시간대 | 대한민국 표준시 |
| %j | 1월 1일부터 경과한 일수 | 001, 002, ..., 366 |
| %U | 1년 중 주차, 일요일이 한 주의 시작이라고 가정 | 00, 01, ..., 53 |
| %W | 1년 중 주차, 월요일이 한 주의 시작이라고 가정 | 00, 01, ..., 53 |
| %c | 날짜, 요일, 시간을 출력. 현재 시간대 기준 | Tue Nov 14 03:50:29 2023 |
| %x | 날짜 출력. 현재 시간대 기준 | 11/14/23 |
| %X | 시간을 출력 | 11:14:22 |
위의 표 내용을 암기할 필요는 없음. 필요할 때마다 찾아보면 됨.
※ strptime() 함수와 strftime() 함수
- strptime(): str 타입으로 된 날짜 데이터를 parsing하여 datetime 객체로 변환하는 함수.
- strftime(): datetime 형태의 데이터를 str 타입으로 변환하는 함수. 단, 우리가 형식을 정의할 때 지정한 형식은 대소문자를 구분하여 정확한 날짜를 표현해야 한다.
[ 넘파이(Numpy) ]
해당 설명에서는 객체라는 표현이 자주 등장한다. 개념이 익숙하지 않은 사람들은 아래의 링크를 참고하자.
참고 자료: https://bing-su-b.tistory.com/124
[ Python 기초 문법 ] - 클래스(1)
프로그래밍 초보들에게 클래스(class) 개념은 넘기 힘든 장벽과도 같을 수 있다. 이 개념을 처음 접하는 독자들도 분명 존재할 것이다. 이번 게시물에서는 클래스가 왜 필요한지, 그렇다면 클래스
bing-su-b.tistory.com
Numpy에서는 날짜와 시간을 datetime64 객체로 표현한다. 파이썬의 datetime.datetime에서는 시간을 마이크로초(10^(-6)) 단위까지 관리한다. 그러나 Numpy의 datetime64는 아토초(10^(-18)) 단위까지 관리한다. Numpy의 날짜와 시간을 이해해야 하는 가장 중요한 이유는 우리가 궁극적으로 사용할 Pandas의 날짜와 시간 함수가 Numpy를 기반으로 만들어졌기 때문이다. Numpy의 날짜와 시간 사용 실습을 진행해 보자.
1) datetime64
- String type으로 객체를 전달하여 날짜를 생성
import numpy as np
np.datetime64('2023-11-14')
# 출력 화면
numpy.datetime64('2023-11-14')- 유닉스 시간을 이용하여 날짜 생성
datetime에 전달하는 첫번째 입력 인자는 수치 데이터, 두번재 입력 인자는 단위를 의미한다. 단위 인자 중 'ns'는 나노초 단위, 'D'는 일 단위 's'는 초 단위를 의미한다. 단위에 따라 출력되는 날짜는 각기 달라진다. 아래의 실습을 통해 확인해 보자.
''' 나노초 단위 사용 예제-1 '''
import numpy as np
np.datetime64(1000, 'ns')
# 출력 화면
numpy.datetime64('1970-01-01T00:00:00.000001000')
''' 나노초 단위 사용 예제-2 '''
np.datetime64(10000000000,'ns')
# 출력 화면
numpy.datetime64('1970-01-01T00:00:10.000000000')
''' 초 단위 사용 예제 '''
np.datetime64(1000000000,'s')
# 출력 화면
numpy.datetime64('2001-09-09T01:46:40')
''' 일 단위 사용 예제 '''
np.datetime64(10000,'D')
# 출력 화면
numpy.datetime64('1997-05-19')2) array() 함수
Numpy의 array() 함수를 사용해서도 날짜를 생성할 수 있다. np.array() 함수에 str 타입의 날짜 리스트를 전달하고, dtype(데이터 타입)을 'datetime64'로 설정하면 된다. 이때 [ ] 안에 넣는 값에 따라 날짜 단위를 지정할 수 있다. 아래의 실습을 통해 확인해 보자.
''' 기본 datetime64 타입으로 지정 -> 일 단위로 지정됨 '''
import numpy as np
np.array(['2007-07-13', '2006-01-13', '2010-08-13'], dtype='datetime64')
# 출력 화면
array(['2007-07-13', '2006-01-13', '2010-08-13'], dtype='datetime64[D]') # 일 단위(D)로 지정됨
''' 월 단위로 지정 '''
np.array(['2007-07-13', '2006-01-13', '2010-08-13'], dtype='datetime64[M]')
# 출력 화면
array(['2007-07', '2006-01', '2010-08'], dtype='datetime64[M]')3) arange() 함수
arange() 함수를 통해 범위를 지정할 수 있다.
''' 달 단위(M)로 지정 '''
import numpy as np
np.arange('2005-02', '2006-03', dtype='datetime64[M]')
# 출력 화면
array(['2005-02', '2005-03', '2005-04', '2005-05', '2005-06', '2005-07',
'2005-08', '2005-09', '2005-10', '2005-11', '2005-12', '2006-01',
'2006-02'], dtype='datetime64[M]')
''' 주 단위(W)로 지정 '''
np.arange('2005-02', '2006-03', dtype='datetime64[W]')
# 출력 화면
array(['2005-01-27', '2005-02-03', '2005-02-10', '2005-02-17',
'2005-02-24', '2005-03-03', '2005-03-10', '2005-03-17',
'2005-03-24', '2005-03-31', '2005-04-07', '2005-04-14',
'2005-04-21', '2005-04-28', '2005-05-05', '2005-05-12',
'2005-05-19', '2005-05-26', '2005-06-02', '2005-06-09',
'2005-06-16', '2005-06-23', '2005-06-30', '2005-07-07',
'2005-07-14', '2005-07-21', '2005-07-28', '2005-08-04',
'2005-08-11', '2005-08-18', '2005-08-25', '2005-09-01',
'2005-09-08', '2005-09-15', '2005-09-22', '2005-09-29',
'2005-10-06', '2005-10-13', '2005-10-20', '2005-10-27',
'2005-11-03', '2005-11-10', '2005-11-17', '2005-11-24',
'2005-12-01', '2005-12-08', '2005-12-15', '2005-12-22',
'2005-12-29', '2006-01-05', '2006-01-12', '2006-01-19',
'2006-01-26', '2006-02-02', '2006-02-09', '2006-02-16'],
dtype='datetime64[W]')
''' 일 단위(D)로 지정 '''
np.arange('2005-02', '2005-03', dtype='datetime64[D]')
# 출력 화면
array(['2005-02-01', '2005-02-02', '2005-02-03', '2005-02-04',
'2005-02-05', '2005-02-06', '2005-02-07', '2005-02-08',
'2005-02-09', '2005-02-10', '2005-02-11', '2005-02-12',
'2005-02-13', '2005-02-14', '2005-02-15', '2005-02-16',
'2005-02-17', '2005-02-18', '2005-02-19', '2005-02-20',
'2005-02-21', '2005-02-22', '2005-02-23', '2005-02-24',
'2005-02-25', '2005-02-26', '2005-02-27', '2005-02-28'],
dtype='datetime64[D]')
''' 시간 단위(h)로 지정 '''
np.arange('2005-02-01', '2005-02-02', dtype='datetime64[h]')
# 출력 화면
array(['2005-02-01T00', '2005-02-01T01', '2005-02-01T02', '2005-02-01T03',
'2005-02-01T04', '2005-02-01T05', '2005-02-01T06', '2005-02-01T07',
'2005-02-01T08', '2005-02-01T09', '2005-02-01T10', '2005-02-01T11',
'2005-02-01T12', '2005-02-01T13', '2005-02-01T14', '2005-02-01T15',
'2005-02-01T16', '2005-02-01T17', '2005-02-01T18', '2005-02-01T19',
'2005-02-01T20', '2005-02-01T21', '2005-02-01T22', '2005-02-01T23'],
dtype='datetime64[h]')4) datetime64를 이용한 날짜 차이 구하기
날짜를 생성할 때 어떤 단위를 전달하는지에 따라 생성되는 범위가 달라진다. 두 날짜의 간격을 구할 때는 단순히 빼면 된다. 그러나 입력되는 두 날짜의 단위가 다를 때는 두 날짜 중 작은 단위의 날짜로 맞춰 계산이 된다. 날짜 단위를 정리하면 아래와 같다. 대소문자의 구분에 주의하여 사용하자.
- Y: 연
- M: 월
- W: 주
- D: 일
- h: 시간
- m: 분
- s: 초
- ms: 밀리초
- us: 마이크로초
- ns: 나노초
- ps: 피코초
- fs: 펨토초
위의 단위를 참고하여 아래의 실습을 수행하며 날짜 계산에 대해 이해해 보자.
import numpy as np
''' 입력된 날짜 범위 다름 -> 일 단위 < 월 단위 '''
np.datetime64('2009-01-01')-np.datetime64('2008-01')
# 출력 화면
numpy.timedelta64(366,'D')
''' 입력된 날짜 범위 동일함 '''
np.datetime64('2009-01-01')-np.datetime64('2008-01-01')
# 출력 화면
numpy.timedelta64(366,'D')
''' 입력된 날짜 범위 다름 -> 연 단위 > 월 단위 '''
np.datetime64('2009')-np.datetime64('2008-01')
# 출력 화면
numpy.timedelta64(12,'M')[ 판다스(Pandas) ]
Pandas는 테이블 데이터 및 시계열 데이터 구조를 조작할 수 있는 라이브러리다. Pandas는 Numpy를 내부적으로 포함하고 있어 날짜 및 시간 관련 기능도 datetime64를 기반으로 이루어져 있다. 대표적인 기능으로는 날짜의 범위 생성, 날짜 변환, 날짜 이동 등이 있다. 또한, Dataframe 객체의 인덱싱 기능은 Data Filtering, Indexing, Pivoting, 정렬, Slicing 등 다양하게 활용이 가능하다. 따라서 Pandas만 잘 활용해도 짧은 코드로 강력한 기능을 구사할 수 있다. 일단 이번 게시물에서는 Pandas의 날짜와 시간 관련 기능을 살펴볼 예정이다.
1) Timestamp와 DatetimeIndex
Pandas에서 하나의 날짜만 사용할 때는 Timestamp로 표현하고 두 개 이상의 배열을 이룰 때는 DatetimeIndex로 표현한다. 실습을 통해 이를 이해해 보자.
- Timestamp() 함수
Timestamp 함수를 사용하여 특정 시점을 나타내는 날짜를 표현할 수 있다. Timestamp 함수 역시 Numpy에서 살펴본 유닉스 시간을 이용한 방식을 사용한다. 즉, UTC 시간 '1970년 1월 1일 00:00:00'부터 인자로 전달된 시간까지 경과 시간을 초 단위로 환산해 나타낸 방식이다. 아래 실습을 통해 해당 내용을 확인해 보자.
''' 디폴트로 나노초 설정이 되어 있음 '''
import pandas as pd
pd.Timestamp(1239.1238934)
# 출력 화면
Timestamp('1970-01-01 00:00:00.000001239')
''' 일 단위로 바꾼 프로그램 '''
pd.Timestamp(1239.1238934, unit='D')
# 출력 화면
Timestamp('1973-05-24 02:58:24.389760')
''' 인자로 날짜가 들어갈 경우 '''
pd.Timestamp('2019-1-1')
# 출력 화면
Timestamp('2019-01-01 00:00:00')- to_datetime() 함수
to_datetime 함수로도 특정 시점의 날짜와 시간을 생성할 수 있다. 한 개의 날짜만 생성하는 경우 호출하는 함수는 다르지만, 내부적으로는 Numpy에서 datetime64를 통해 날짜를 만드는 것과 같다. Pandas 내부적으로 Numpy가 동작한다는 내용을 아래의 실습으로 확인할 수 있다.
''' Pandas의 to_datetime 함수로 날짜 생성 '''
import pandas as pd
pd.to_datetime('2019-1-1')
# 출력 화면
Timestamp('2019-01-01 00:00:00')
''' Numpy의 datetime64 함수로 날짜 생성 '''
import numpy as np
np.datetime64('2019-01-01')
# 출력 화면
numpy.datetime64('2019-01-01')그러나 to_datetime 함수에 날짜들의 리스트를 인자로 전달할 경우 범위, 즉, DatetimeIndex를 표현하게 된다. 이 경우 DatetimeIndex라는 클래스로 배열이 생성되고, Data type은 datetime64[ns]로 표현되는 것을 확인할 수 있다. 아래의 실습을 통해 해당 내용을 확인해 보자.
import pandas as pd
pd.to_datetime(['2018-1-1', '2019-1-2'])
# 출력 결과
DatetimeIndex(['2018-01-01', '2019-01-02'], dtype='datetime64[ns]', freq=None)- date_range() 함수
date_range() 함수는 특정 기간의 날짜를 자동 생성한다. 예를 들면 '2023-01'과 '2023-02'를 전달하면 출력 결과는 2월 1일자 데이터까지만 생성된다. 간단하게 생각하면, 두번째 인자로 전달된 값의 달은 고려하지 않는다. 추후 데이터를 생성하거나 가공할 때 이러한 점을 주의해야 한다.
import pandas as pd
pd.date_range('2023-01', '2023-02')
# 출력 화면
DatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08',
'2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12',
'2023-01-13', '2023-01-14', '2023-01-15', '2023-01-16',
'2023-01-17', '2023-01-18', '2023-01-19', '2023-01-20',
'2023-01-21', '2023-01-22', '2023-01-23', '2023-01-24',
'2023-01-25', '2023-01-26', '2023-01-27', '2023-01-28',
'2023-01-29', '2023-01-30', '2023-01-31', '2023-02-01'],
dtype='datetime64[ns]', freq='D')2) Period와 PeriodIndex
- pd.Period()
- pd.Period_range()
Period와 PeriodIndex는 특정 시점이 아니라 기간을 포괄하는 함수다. 그래서 freq 인자를 옵션으로 사용할 수 있다. Period() 함수는 기본적으로 인자를 월 단위(freq='M')로 인식한다. 그러나 매개변수 freq를 일간('D')으로 설정하면 일 단위로 생성되는 것을 확인할 수 있다. 이를 확인하는 실습을 진행해 보자.
''' 월 단위로 날짜 생성 '''
import pandas as pd
pd.Period('2023-01', 'M')
# 출력 화면
Period('2023-01', 'M')
''' 일 단위로 날짜 생성 '''
pd.Period('2023-05', freq='D')
# 출력 화면
Period('2023-05-01', 'D')
두 개 이상의 str 타입을 가지는 날짜 데이터를 전달하면 PeriodIndex 클래스로 묶인다. 이를 확인해 보자.
import pandas as pd
# 2023-01부터 2023-02까지 날짜 생성
pd.period_range('2023-01', '2023-02', freq='D')
# 출력 화면
PeriodIndex(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08',
'2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12',
'2023-01-13', '2023-01-14', '2023-01-15', '2023-01-16',
'2023-01-17', '2023-01-18', '2023-01-19', '2023-01-20',
'2023-01-21', '2023-01-22', '2023-01-23', '2023-01-24',
'2023-01-25', '2023-01-26', '2023-01-27', '2023-01-28',
'2023-01-29', '2023-01-30', '2023-01-31', '2023-02-01'],
dtype='period[D]')3) Timestamp vs Period
앞서 배운 pd.Period()와 pd.Timestamp()의 차이를 비교 연산을 통해 이해해 보자.
import pandas as pd
p = pd.Period('2023-11-21')
test = pd.Timestamp('2023-11-21 16:45')
# p.start_time: p에 저장된 2023-11-21의 시작 시간(00:00:00)
# p.end_time: p에 저장된 2023-11-21의 종료 시간(23:59:59.999999999)
p.start_time < test < p.end_time
# 출력 화면
TrueTimestamp 함수는 특정 시점을 생성하고, Period는 하루의 시작 시점부터 종료 시점까지의 범위를 포괄하여 날짜를 생성한다.
[ FinanceDataReader ]
FinanceDataReader는 한국 주식 가격, 미국 주식 가격, 지수, 환율, 암호 화폐 가격, 종목 리스트 등을 제공하는 API 패키지다. 우선 해당 패키지를 설치하기 위해 Jupyter Notebook의 터미널로 이동하자.

터미널에 아래의 명령어를 입력하여 패키지를 설치하자.
pip install -U finance-datareader
FinanceDataReader 패키지는 fdr로 임포트하는 것이 관례다.
import FinanceDataReader as fdr1) 종목 리스트 가져오기
StockListing() 함수에 특정 심볼을 전달하면, 해당 심볼에 등록된 전체 종목 리스트가 출력된다. 종목 데이터 전체를 얻기 위해 사용할 수 있는 거래소 심볼은 아래와 같다.
| 한국 | 미국 | ||
| 심볼 | 거래소 | 심볼 | 거래소 |
| KRX | 한국거래소 종목 | NASDAQ | 나스닥 종목 |
| KOSPI | 코스피 종목 | NYSE | 뉴욕 증권거래소 종목 |
| KOSDAQ | 코스닥 종목 | AMEX | AMEX 종목 |
| KONEX | 코넥스 종목 | SP500 | S&P 500 종목 |
※ KRX는 KOSPI, KOSDAQ, KONEX 모두 포함.
예를 들어 'KRX' 심볼을 전달하면, 한국 거래소에 상장된 전체 종목 리스트를 출력한다. 아래의 실습을 통해 확인해 보자.
import FinanceDataReader as fdr
df_krx=fdr.StockListing('KRX')
# df_krx 타입 확인
print(type(df_krx))
# df_krx 출력
print(df_krx)
# 출력 화면
<class 'pandas.core.frame.DataFrame'> # 판다스의 데이터프레임 타입
Code ISU_CD Name Market Dept Close ChangeCode \
0 005930 KR7005930003 삼성전자 KOSPI 72800 1
1 373220 KR7373220003 LG에너지솔루션 KOSPI 447000 1
2 000660 KR7000660001 SK하이닉스 KOSPI 132000 1
3 207940 KR7207940008 삼성바이오로직스 KOSPI 722000 1
4 005935 KR7005931001 삼성전자우 KOSPI 57500 3
... ... ... ... ... ... ... ...
2773 021045 KR7021041009 대호특수강우 KOSDAQ 중견기업부 7030 2
2774 245450 KR7245450002 씨앤에스링크 KONEX 일반기업부 1699 2
2775 288490 KR7288490006 나라소프트 KONEX 일반기업부 62 1
2776 308700 KR7308700004 테크엔 KONEX 일반기업부 641 2
2777 322190 KR7322190000 베른 KONEX 일반기업부 135 1
Changes ChagesRatio Open High Low Volume Amount \
0 100 0.14 73100 73400 72700 9696278 708597027600
1 3000 0.68 450000 452000 444000 157680 70620684000
2 600 0.46 132000 133300 131600 2431371 322078229400
3 2000 0.28 724000 726000 719000 32754 23642562000
4 0 0.00 57700 57800 57400 813557 46825083068
... ... ... ... ... ... ... ...
2773 -40 -0.57 7050 7070 7020 681 4790770
2774 -1 -0.06 1699 1699 1699 1 1699
2775 2 3.33 61 62 58 88109 5274437
2776 -3 -0.47 641 641 641 1 641
2777 16 13.45 135 135 135 1 135
Marcap Stocks MarketId
0 434600169640000 5969782550 STK
1 104598000000000 234000000 STK
2 96096312180000 728002365 STK
3 51387628000000 71174000 STK
4 47315985250000 822886700 STK
... ... ... ...
2773 2982449380 424246 KSQ
2774 2684352040 1579960 KNX
2775 2682554310 43267005 KNX
2776 2564000000 4000000 KNX
2777 1204901595 8925197 KNX
[2778 rows x 17 columns]StockListing() 함수 미국 'S&P500' 심볼을 전달하면, S&P500 지수에 등록된 전체 종목 리스트를 출력할 수 있다. 또한, head() 메서드를 사용하면 생성된 데이터프레임에서 상위 5개의 샘플만을 출력할 수 있다.
import FinanceDataReader as fdr
df_spx = fdr.StockListing('S&P500')
df_spx.head()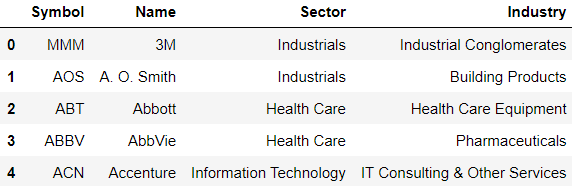
해당 데이터프레임에 몇 개의 Sample이 존재하는지 확인해 보자.
print('s&p 종목 데이터프레임의 크기 :', len(df_spx))
# 출력 화면
s&p 종목 데이터프레임의 크기 : 5032) 가격 가져오기
지금까지는 종목 리스트를 가져오는 방법에 대해 다뤘다. 이제 가격 데이터를 가져오는 방법에 대해 살펴볼 것이다.
- 종목 코드 검색
가격 데이터를 가져오기 위해서는 종목 코드가 필요하다. 아래와 같이 종목을 검색할 수 있다.
import FinanceDataReader as fdr
df = fdr.StockListing('KRX') # 한국거래소 종목 리스트를 df에 저장
name = '삼성전자' # 검색어(찾고자 하는 종목명)
df_filter = df.loc[df['Name'] == name] # 종목 검색(검색어 전체 일치)
df_filter # 일치하는 종목 출력
빨간 박스의 코드를 이용하여 가격 데이터를 가져올 예정이다. 주가 확인을 위한 코드는 아래와 같이 저장할 수 있다.
code = df_filter.loc[0, 'Code'] # [index, 'column 명']
아래와 같이 일부의 단어만을 검색할 수도 있다.
import FinanceDataReader as fdr
df = fdr.StockListing('KRX')
name = '에너지솔루션' # 검색어
df_filter = df.loc[df['Name'].str.contains(name)] # 검색어를 포함하는 종목명을 df_filter에 저장
df_filter # 일치하는 종목 출력
검색 결과에서 찾고자 하는 Code만 저장하면 된다. 예를 들어 LG에너지솔루션의 코드는 아래와 같이 저장할 수 있다.
code = df_filter.loc[1, 'Code'] # [index, 'column 명']- 주가 정보 가져오기
가격 정보를 불러오기 위해서는 DataReader() 함수를 사용하면 된다. 해당 함수의 사용법은 아래와 같다.
fdr.DataReader('Code', 'Start_Date', 'End_Date')시작 날짜와 종료 날짜는 생략이 가능하며, 생략 시에는 전체 데이터를 확인할 수 있다. 위에서 확인한 LG에너지솔루션의 가격 데이터를 확인해 보자.
import FinanceDataReader as fdr
df = fdr.StockListing('KRX')
name = '에너지솔루션'
df_filter = df.loc[df['Name'].str.contains(name)]
code = df_filter.loc[1, 'Code']
# 전체 데이터 수집
df_result = fdr.DataReader(code)
df_result
종료 날짜를 생략하면 시작 날짜부터 현재까지의 데이터가 수집된다.
import FinanceDataReader as fdr
df = fdr.StockListing('KRX')
name = '에너지솔루션'
df_filter = df.loc[df['Name'].str.contains(name)]
code = df_filter.loc[1, 'Code']
df_result = fdr.DataReader(code, '2023-01-01')
df_result
상위 10개의 데이터를 출력하고 싶을 경우에는 head() 함수를 이용하면 된다.
import FinanceDataReader as fdr
df = fdr.StockListing('KRX')
name = '에너지솔루션'
df_filter = df.loc[df['Name'].str.contains(name)]
code = df_filter.loc[1, 'Code']
df_result = fdr.DataReader(code, '2023-01-01')
df_result.head(10)
미국 종목 데이터를 가져올 때는 ticker 명을 사용한다. ticker란, 미국에서 사용하는 종목 코드다.
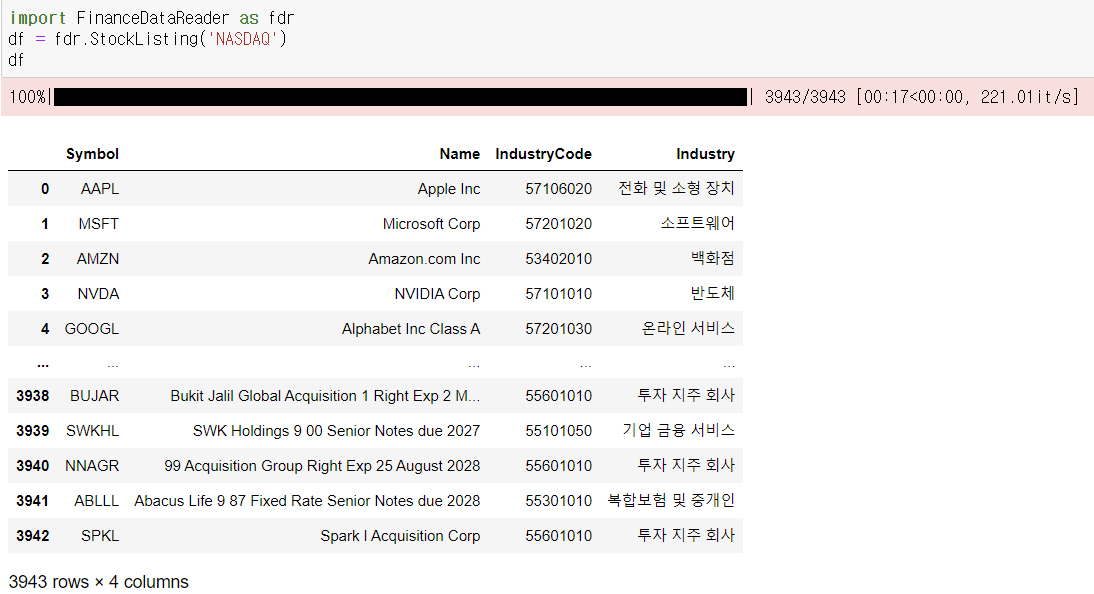
미국 종목 코드에 해당하는 column 이름은 Symbol이다.
아래 정리된 FinanceDataReader 패키지의 속성을 참고하여 다양한 값을 호출할 수 있다.
<< 거래소별 전체 종목 코드 - StockListing() 함수 >>
- 한국 거래소: KRX(KOSPI, KOSDAQ, KONEX)
- 미국 거래소: NASDAQ, NYSE, AMEX, S&P500
<< 가격 데이터 - DataReader() 함수 이용 >>
- 국내 주식: 005930(삼성전자), 091990(셀트리온헬스케어) 등
- 해외 주식: AAPL(애플), AMZN(아마존), GOOGL(구글) 등
- 각종 지수: KS11(코스피 지수), KQ11(코스닥 지수), DJI(다우 지수), IXIC(나스닥 지수), US500(S&P500 지수)
- 환율 데이터: USD/KRX(원달러 환율), USD/EUR(달러당 유로화 환율), CNY/KRX(위안화 원화 환율)
- 암호 화폐 가격: BTC/USD(비트코인 달러 가격, 비트파이넥스), BTC/KRW(비트코인 원화 가격, 빗썸)
자세한 기능은 아래의 메뉴얼을 참고하면 된다.
참고 링크: https://financedata.github.io/posts/finance-data-reader-users-guide.html
FinanceDataReader 사용자 안내서
FinanceDataReader 사용자 안내서
financedata.github.io
- 가격 데이터 로드 예시
# 애플(AAPL), 2018-01-01 ~ 2018-03-30
import FinanceDataReader as fdr
df = fdr.DataReader('AAPL', '2018-01-01', '2018-03-30')
df
# 코스피 지수(KS11), 2015년~현재
import FinanceDataReader as fdr
df = fdr.DataReader('KS11', '2015')
df
# 원달러 환율(USD/KRW), 2004년~현재
import FinanceDataReader as fdr
df = fdr.DataReader('USD/KRW', '2004')
df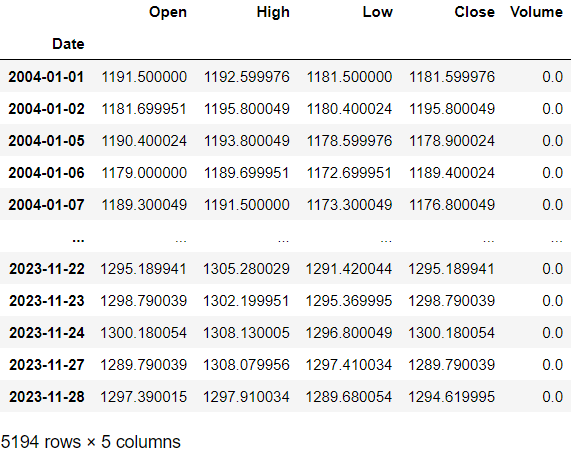
반응형
LIST
'Study > Finance Data Analytics' 카테고리의 다른 글
| [ Python ] 데이터 분석을 위한 패키지 - Pandas (0) | 2023.11.07 |
|---|---|
| [ Python ] 금융 데이터 분석을 위한 실습 환경 준비하기(2) (1) | 2023.08.03 |
| [ Python ] 금융 데이터 분석을 위한 실습 환경 준비하기(1) (0) | 2023.08.03 |





댓글 영역